
구글 검색 등록을 하다 보면 구글 서치 콘솔에서 "색인 생성 요청이 거부됨" 실시간 테스트 중에 URL에서 색인 생성 문제가 감지되었습니다.
이렇게 표시되어 구글에 등록이 불가능 한 경우가 있습니다. 해외 IP나 지역을 차단하는 경우가 있고 방화벽에서 차단하는 경우가 있어 아래와 같이 참고 해 주세요.
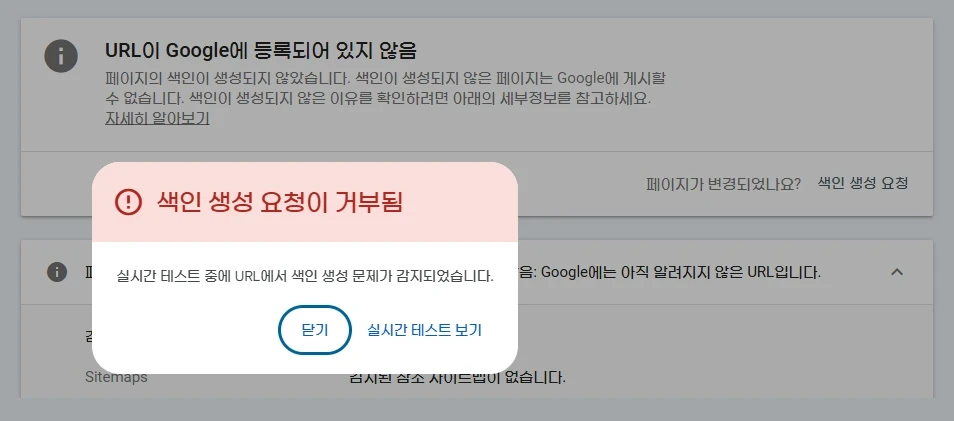

Google Search Console 수집 거부의 핵심 원인
서버에서 해외 IP를 차단(KR-only)하면 Googlebot도 함께 차단되어 검색 색인이 불가능하다.
해외 IP 차단이 검색 색인 거부로 이어지는 이유
Googlebot은 미국 기반의 해외 IP를 사용해 웹사이트에 접근한다. 따라서 서버나 방화벽에서 해외 접속을 제한하면 Googlebot 역시 접근이 불가능해지고 Search Console에서 ‘수집 거부’, ‘호스트 로딩 실패’, ‘접근 불가’ 오류가 발생한다.
Sucuri에서 “방화벽 없음”이 떠도 해외 차단과 무관
Sucuri SiteCheck는 Cloudflare WAF, ModSecurity 등 웹 방화벽 여부만 감지한다. 서버의 국가 기반 IP 차단(firewalld, iptables, 보안 솔루션) 같은 시스템 방화벽은 감지하지 못하므로, Sucuri에서 정상으로 떠도 해외 차단은 충분히 존재할 수 있다.
해외 차단 여부를 정확히 확인하는 방법
해외 접속 상태는 Geopeeker와 Uptrends 같은 글로벌 테스트 도구로 확인해야 한다. 한국에서는 접속되지만 해외 지역에서 타임아웃 또는 차단이 뜨면 서버에서 국가 기반 차단이 활성화된 것이다.
Googlebot 차단 여부 확인과 인증 방식
Google은 정적 IP 표를 제공하지 않고, Reverse DNS 인증 또는 JSON 기반 IP 범위를 통해 크롤러를 검증하도록 안내한다.
1) Reverse DNS 인증 방식
가장 정확하며 Google이 권장하는 방식이다.
1. 요청 IP → PTR 조회 → 도메인이 *.googlebot.com 또는 *.google.com 인지 확인 2. 해당 도메인을 다시 A 레코드 조회 → 원래 IP와 일치해야 함
User-Agent만으로 Googlebot을 믿는 것은 매우 위험하며, Reverse DNS 검증이 반드시 필요하다.
2) JSON 기반 Google 크롤러 IP 범위
Google은 모든 크롤러·페처 IP를 JSON 형태로 제공한다.
https://developers.google.com/crawling/docs/crawlers-fetchers/verify-google-requests
해당 JSON은 수시로 갱신되므로, 방화벽 화이트리스트 설정 시 최신 상태를 반영해야 한다.
Googlebot 접속 허용 설정 방법
해외 IP 차단 정책을 유지하면서 검색 색인을 정상화하려면 Googlebot의 IP 또는 DNS 인증만 예외 허용해야 한다.
1) firewalld에서 Googlebot IP 대역 허용
Googlebot이 주로 사용하는 대역 예시는 다음과 같다.
66.249.64.0/19 66.102.0.0/20 64.233.160.0/19 72.14.192.0/18 209.85.128.0/17 216.239.32.0/19 74.125.0.0/16
firewalld 명령어 예시:
firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="66.249.64.0/19" accept' firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="66.102.0.0/20" accept' firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="64.233.160.0/19" accept' firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="72.14.192.0/18" accept' firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="209.85.128.0/17" accept' firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="216.239.32.0/19" accept' firewall-cmd --reload
2) Apache에서 Googlebot DNS 기반 허용
Require host googlebot.com Require host google.com
3) 해외 차단 + Googlebot 허용 조합이 최적
해외 접속 차단을 유지하면서 SEO도 보존하려면 Googlebot만 정상적으로 접근하도록 예외 설정이 필요하다. 이를 적용하면 Search Console 수집 오류가 정상적으로 해결된다.
업체나 고객에게 보낼 안내문 예시
서버에서 해외 IP 차단(KR-only)이 활성화된 경우 Googlebot도 차단되어 Search Console에서 ‘수집 거부’ 오류가 발생합니다. Googlebot은 해외 IP를 사용하므로 다음 조치 중 하나가 필요합니다. 1) 해외 IP 전체 허용 2) Googlebot IP 대역 화이트리스트(JSON 기준) 3) Reverse DNS 기반 Googlebot 예외 허용 조치 후 Google 검색 색인이 정상 진행됩니다.
진짜 구글봇인지, 구글이라고 사칭한 가짜 트래픽인지 확인하는 방법
구글봇인지 확실히 검증하려면 User-Agent 믿지 말고 IP 기반 2단계 DNS 검증을 해라.
https://developers.google.com/crawling/docs/crawlers-fetchers/verify-google-requests
